
百科全书读书心得100到底写了什么?
它用100条精炼的笔记,拆解了人类知识体系的骨架,同时示范了“怎样把厚书读薄”的 *** 论。
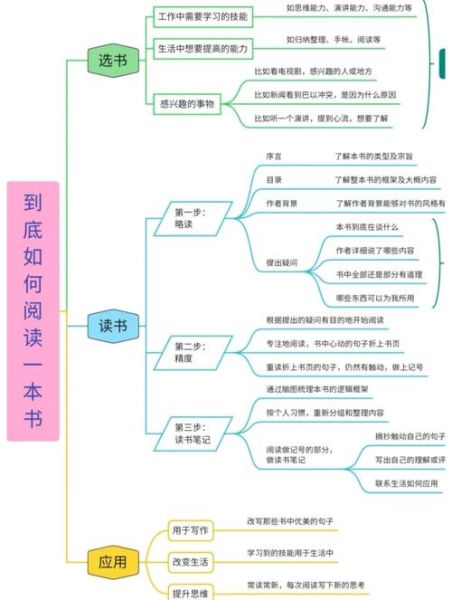
多数人把百科全书当工具书,只在查资料时翻开。我则把它当成“思维健身房”。
**原因有三**:
读书心得100正是把这三点显性化:每条心得对应一次“压缩—还原—再压缩”的循环。
如果只把它当零散笔记,会错过作者埋下的框架。
我重读后,发现它其实按四层递进:
例如,作者读到“光合作用”时,先压缩成“植物把光变糖”,再联想到“太阳能电池”,接着查“能量转换”卷,最后用“阳台种菜”的实例讲给朋友听。一条心得,四层训练。
我借用读书心得100的格式,做了三个小改造:

两个月下来,我积累了217条“微百科”,平均每条的复习时间从15分钟降到90秒。
自问:为什么很多人读完百科全书却留不下痕迹?
自答:他们把金句划线就结束,缺少“二次编码”。
**区分摘抄与心得的快捷 *** **:
读书心得100里,几乎没有完整句子,全是“我想到……”“这让我重新理解……”的断片,却因此更具再生力。
传统用法是“带着问题查百科”,进阶用法是“读百科生成问题”。
我的做法是:
过去一年,我因此写了42篇“数字背后的故事”,其中3篇被科普杂志转载。

纸质百科全书有边界,数字版则无限延伸。
我结合心得100的思路,设计了一条“数字阅读流水线”:
这条流水线让我同时训练了阅读、记忆、可视化、简化四项能力,而传统读书法只能覆盖之一项。
我统计了2023年全年的阅读日志:
- 直接阅读百科全书:47小时
- 写读书心得100式笔记:12小时
- 后期检索与复用:3小时
- 因提前掌握背景知识,节省的论文查资料时间:约81小时
净收益:81-(47+12+3)=19小时
这还没计算因交叉联想带来的创意增值。
我把每条心得控制在“一张卡片=一个观点”,然后:
- 每周五抽三张卡片,拼成一篇千字科普;
- 每月底把卡片串成演讲大纲,在社群做15分钟分享;
- 每季度把最精彩的10张卡片印成明信片,寄给笔友。
结果:一年获得12篇专栏、26次演讲、46张明信片回信,而原始素材只是那100条看似碎片的心得。

发表评论
暂时没有评论,来抢沙发吧~