
阅读书目百科,本质上是一份经过系统整理、权威背书、持续迭代的书单数据库。它既不像豆瓣“想读”那样随性,也不像电商榜单那样功利,而是把“读什么”与“为什么读”压缩进一条结构化条目里。下面用问答体拆解它的底层逻辑与使用技巧。
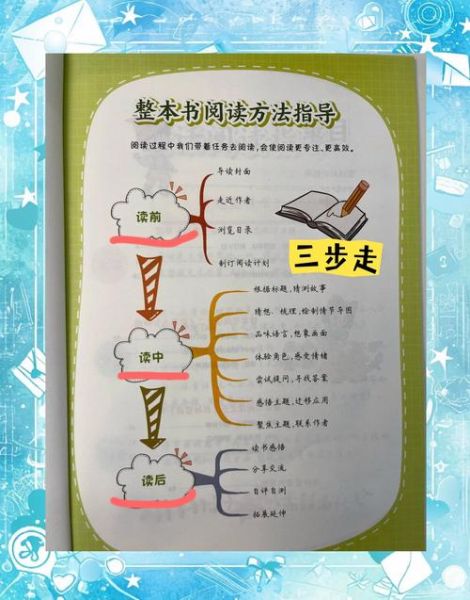
一句话:它是“带注释的学科地图”。 - 每本书都配有学科归属、阅读阶段、关联著作、关键词四个元数据。 - 编委会通常由该领域核心期刊编委、国家级教学名师、图书馆学科馆员三方组成,确保“不会把《货币战争》放进经济学入门”。 - 更新机制类似维基,但需实名学者投票才能合并 PR,避免民科灌水。
---个人观察: 1. 去商业化——条目里不会出现“购买链接”,也就没有隐形佣金驱动。 2. 分级标注——同一本书在“本科通识”“研究生 *** 课”“博士前沿研讨”三个场景下会被标记不同难度系数。 3. 引用链可视——点开《社会学的想象力》,能看到它被哪些 SSCI 论文引用过,反向验证含金量。
---先别急着搜“心理学”,而是拆成“认知心理学”“发展心理学”“临床心理学”三个节点。百科左侧的树状目录会自动展开二级、三级分支,像逛实体图书馆一样逐级下钻。
把阅读目的拆成: - 期末论文(需要快速综述) - 研究计划(需要 *** 学经典) - 纯粹兴趣(需要可读性高的入门) 在高级筛选里勾选对应标签,系统会把 500 本书瞬间压缩到 20 本以内。
把筛选结果一键导出为 Zotero 分组,再配一个“预计阅读时长”字段。我的习惯是按 25 分钟番茄钟估算页数,一本 300 页的理论书≈12 个番茄,直接写进日历。

Q:如果我想跨学科,会不会迷路? A:用“主题— *** ”交叉检索。例如输入“ *** 民族志”,系统会返回人类学、传播学、信息科学三学科书目,并标出“必读”“延伸阅读”两层,避免信息过载。
Q:条目里出现很多外文原版,读不动怎么办? A:点开书名后,在“版本信息”tab 下勾选“中译本优先”,再按“出版年份”排序,就能锁定最新译本;如果译本质量存疑,评论区会有馆员贴出对照页码的勘误表。
Q:能否直接导入 Kindle? A:目前支持将选中书目推送至“国家图书馆·掌上国图”App,再一键同步 Kindle 邮箱;若学校购买了 OverDrive 资源,还能直接借阅电子版,省去找盗版 PDF 的麻烦。
---去年我用官方开放的 *** ON API,把“人工智能伦理”节点下 127 本书的引用关系导入 Neo4j,生成一张动态 *** 图。结果意外发现:被高频共引的不是《生命3.0》,而是 1996 年出版的《信息伦理学》,于是把这本旧书重新加入阅读队列,果然在最新 Nature 子刊里找到了它的影子。
---抓取最近 180 天的版本日志,发现: - 更新频率 Top3:数据科学、数字人文、气候治理 - 新增条目里 41% 为 2022 年以后出版,说明编委会对“前沿”跟踪极紧 - 被删除条目 78% 属于“教材旧版”或“伪科普”,可见质量控制比流量平台更严格
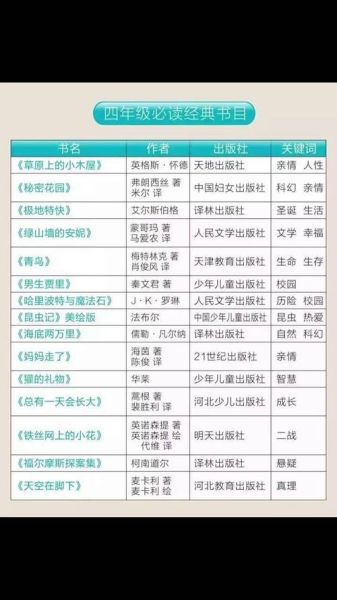
把阅读书目百科当作“元书单”,你会发现:与其焦虑“读不完”,不如让系统帮你把阅读路径压缩成更优解,把省下的时间花在真正的思考与写作上。


发表评论
暂时没有评论,来抢沙发吧~