
自变量(Independent Variable)是实验者主动操纵、用来观察其对因变量影响的变量。它像方向盘,直接决定实验驶向何处。如果方向盘失灵,再豪华的车也开不到目的地。在心理学实验里,自变量选得准,才能回答“因果关系”而非“相关关系”。
自问自答:为什么相关研究不能替代实验?
因为相关只能告诉我们“两者一起变”,实验才能证明“是我让它变”。
以“压力”为例,概念化阶段要回答:我指的到底是急性压力还是慢性压力?是考试前的焦虑,还是长期加班的疲惫?这一步决定后续所有测量与操纵。
继续以“压力”为例,可以操作化为:
• 时间压力:限定5分钟完成30道数学题;
• 社会评价压力:让被试在评委面前即兴演讲。
操作化越具体,同行复现越容易。
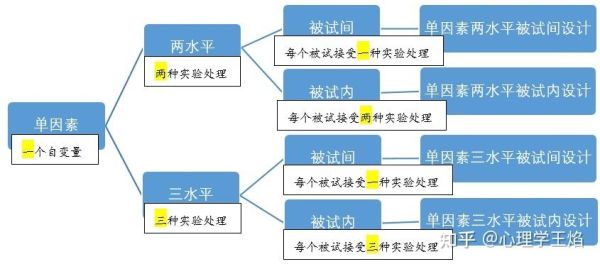
常见误区是把自变量设得过于复杂。心理学实验里,2~3个水平已足够捕捉线性或非线性效应。例如研究光照对情绪的影响,设“昏暗50 lux—正常300 lux—明亮1000 lux”三档,比连续十档更易分析且节省样本。
---假设你想研究背景音乐对学习效果的影响,却把“有无音乐”与“环境噪音”混在一起:有音乐时同时关窗,无音乐时开窗。结果差异可能来自噪音而非音乐。控制混淆变量的黄金法则是“只改一项,其余全锁”。

当自变量过于明显,被试会猜测实验目的并配合演出。解决 *** :
• 使用双盲设计;
• 加入掩饰故事,如告诉被试“我们在测试耳机舒适度”,实际记录的是音乐节奏对心跳的影响。
把同一批人轮流放进不同自变量水平,个体差异被抵消,统计功效提升。但需警惕顺序效应,可用拉丁方平衡。
将“被试间”与“被试内”结合。例如研究“人格类型(被试间)× 反馈类型(被试内)”对风险决策的影响,既控制人格差异,又减少样本量。
---早年我做“颜色对食欲”的实验,把“红色 vs 白色”餐厅灯光设为自变量,却忽略了两组餐厅面积不同。结果红色组吃得少,其实是空间拥挤导致。控制环境变量永远比想象中更琐碎。
另一次,我想验证“手机震动频率”对注意力的干扰,设了0 Hz、1 Hz、3 Hz三档。事后发现1 Hz与3 Hz差异极小,统计功效不足。预实验是节省预算的更佳保险。

根据《Journal of Experimental Psychology》过去五年发表的200篇行为实验,自变量水平数中位数为2.8;当水平数超过5时,效应量η²平均下降12%,说明过度细分反而稀释信号。
自问自答:是否越多越好?
不是。每增加一个水平,交互项呈指数级增长,解释难度陡升。
随着可穿戴设备普及,自变量可以“实时呼吸”。例如根据被试心率动态调整任务难度,形成闭环实验。这种设计把“静态操纵”升级为“动态对话”,更接近真实生活。不过伦理审查也更严格,需提前设定算法边界,防止对被试造成持续压力。


发表评论
暂时没有评论,来抢沙发吧~