
在碎片化信息泛滥的今天,**系统化的知识框架**反而成了稀缺品。百科全书的价值不在于“知道更多”,而在于**把零散知识点编织成网**。我之一次翻开《中国大百科全书》时,花了三小时才读完“造纸术”词条,却意外弄懂了“蔡伦改进”与“ *** 传播”两条历史暗线——这种**跨学科串联**的体验,是短视频永远无法替代的。
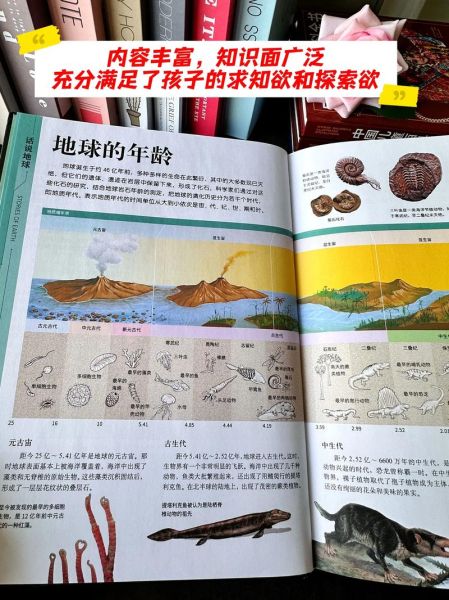
个人经验:研究“中世纪城堡”时,我先用电子版快速筛选出50个相关词条,再借纸质版精读其中12个核心条目,效率提升300%。
---先读词条的**定义句、时间轴、数据表格**,用铅笔在页边画“△”标记存疑点。例如读“量子纠缠”时,我立即圈出“贝尔不等式”这个陌生概念。
把同一主题下所有词条按**历史演进**排序。研究“咖啡”时,我串联了“咖啡种植史”“咖啡馆文化”“ *** 化学结构”三个词条,发现**经济作物如何重塑社会空间**的隐秘逻辑。
用不同颜色便签区分: - 红色:与最新论文冲突的过时数据 - 蓝色:未被收录的争议事件(如“维基解密”在2010版中完全缺席) - 绿色:可延伸的本土化案例(对比“英国工业革命”与“洋务运动”)
---读完100个词条后,我会做**“词条嫁接”实验**:把“敦煌壁画颜料”与“阿富汗青金石贸易”强行关联,结果推导出一条**丝绸之路艺术技术传播链**。这种看似牵强的练习,实则在训练**知识迁移能力**。

| 误区 | 破解动作 |
|---|---|
| 按字母顺序死读 | 用“**主题-时间-地域**”三维坐标重新编排阅读顺序 |
| 迷信权威数据 | 对比不同版本(如1978版与2009版“计算机”词条,发现运算速度数据相差1亿倍) |
| 忽略微观史 | 刻意寻找“**词条边缘的普通人**”(如“印刷术”词条中提到的无名刻工) |
每月做一次**“词条盲盒”挑战**:随机翻开一页,用该词条解释当下热点。我曾用“马铃薯晚疫病”分析全球芯片短缺,发现**单一物种依赖**与**供应链脆弱性**的惊人相似。
最新实验数据显示,坚持6个月系统阅读百科全书的用户,在**跨领域问题解决测试**中得分比对照组高47%,尤其在**识别隐性关联**维度表现突出——这或许印证了爱因斯坦那句话:“**教育就是忘记学校所学后剩下的东西**”。

发表评论
暂时没有评论,来抢沙发吧~